

How To Set Up An Engineering Notebook
Get started with Databricks as a data engineer
The goal of a data engineer is to take data in its near raw class, enrich it, and make information technology easily bachelor to other authorized users, typically data scientists and data analysts. This quickstart walks you lot through ingesting data, transforming it, and writing it to a table for easy consumption.
Data Science & Technology UI

From the sidebar at the left and the Common Tasks list on the landing page, you admission key Databricks Data Scientific discipline & Applied science entities: the Workspace, clusters, tables, notebooks, jobs, and libraries. The Workspace is the special root folder that stores your Databricks assets, such as notebooks and libraries, and the data that yous import.
Get help
To get help, click ![]() Aid in the lower left corner.
Aid in the lower left corner.

Pace 1: Create a cluster
In order to exercise exploratory data assay and data engineering, you must first create a cluster of computation resource to execute commands confronting.
-
Log into Databricks and make sure yous're in the Data Science & Engineering workspace.
Encounter Data Science & Engineering UI.
-
In the sidebar, click
 Compute.
Compute. -
On the Compute folio, click Create Cluster.

-
On the Create Cluster page, specify the cluster name Quickstart, have the remaining defaults, and click Create Cluster.
Step 2: Ingest data
The easiest style to ingest your information into Databricks is to apply the Create Table Wizard. In the sidebar, click ![]() Data and then click the Create Tabular array push.
Data and then click the Create Tabular array push.

On the Create New Table dialog, elevate and drop a CSV file from your reckoner into the Files section. If you need an example file to exam, download the diamonds dataset to your local estimator and drag it to upload.

-
Click the Create Table with UI button.
-
Select the Quickstart cluster you created in stride 2.
-
Click the Preview Tabular array button.
-
Ringlet down to see the Specify Tabular array Attributes section and preview the data.
-
Select the Beginning row is header option.
-
Select the Infer Schema choice.
-
Click Create Table.
You lot have successfully created a Delta Lake table that can be queried.
Additional data ingestion options
Alternatively, you tin can click the Create Tabular array in Notebook button to audit and modify code in a notebook to create a tabular array. Y'all can use this technique to generate code for ingesting data from other data sources such equally Redshift, Kinesis, or JDBC past clicking the Other Information Sources selector.
If at that place are other data sources to ingest data from, like Salesforce, you tin can easily leverage Databricks partner past clicking  Partner Connect in the sidebar. When you select a partner from Partner Connect, you lot can connect the partner's application to Databricks and even beginning a gratuitous trial if you are not already a client of the partner. Come across Databricks Partner Connect guide.
Partner Connect in the sidebar. When you select a partner from Partner Connect, you lot can connect the partner's application to Databricks and even beginning a gratuitous trial if you are not already a client of the partner. Come across Databricks Partner Connect guide.
Stride iii: Query data
A notebook is a collection of cells that run computations on a cluster. To create a notebook in the workspace:
-
In the sidebar, click
 Workspace.
Workspace. -
In the Workspace binder, select
 Create > Notebook.
Create > Notebook.
-
On the Create Notebook dialog, enter a proper name and select Python in the Default Language drop-downwardly.
-
Click Create. The notebook opens with an empty prison cell at the peak.
-
Enter the following code in the first cell and run it past clicking SHIFT+ENTER.
df = table ( "diamonds_csv" ) brandish ( df )
The notebook displays a table of diamond color and average price.
 .
. -
Create some other cell, this time using the
%sqlmagic command to enter a SQL query:% sql select * from diamonds_csv
You lot can use the %sql, %r, %python, or %scala magic commands at the commencement of a prison cell to override the notebook's default linguistic communication.
-
Click SHIFT+ENTER to run the command.
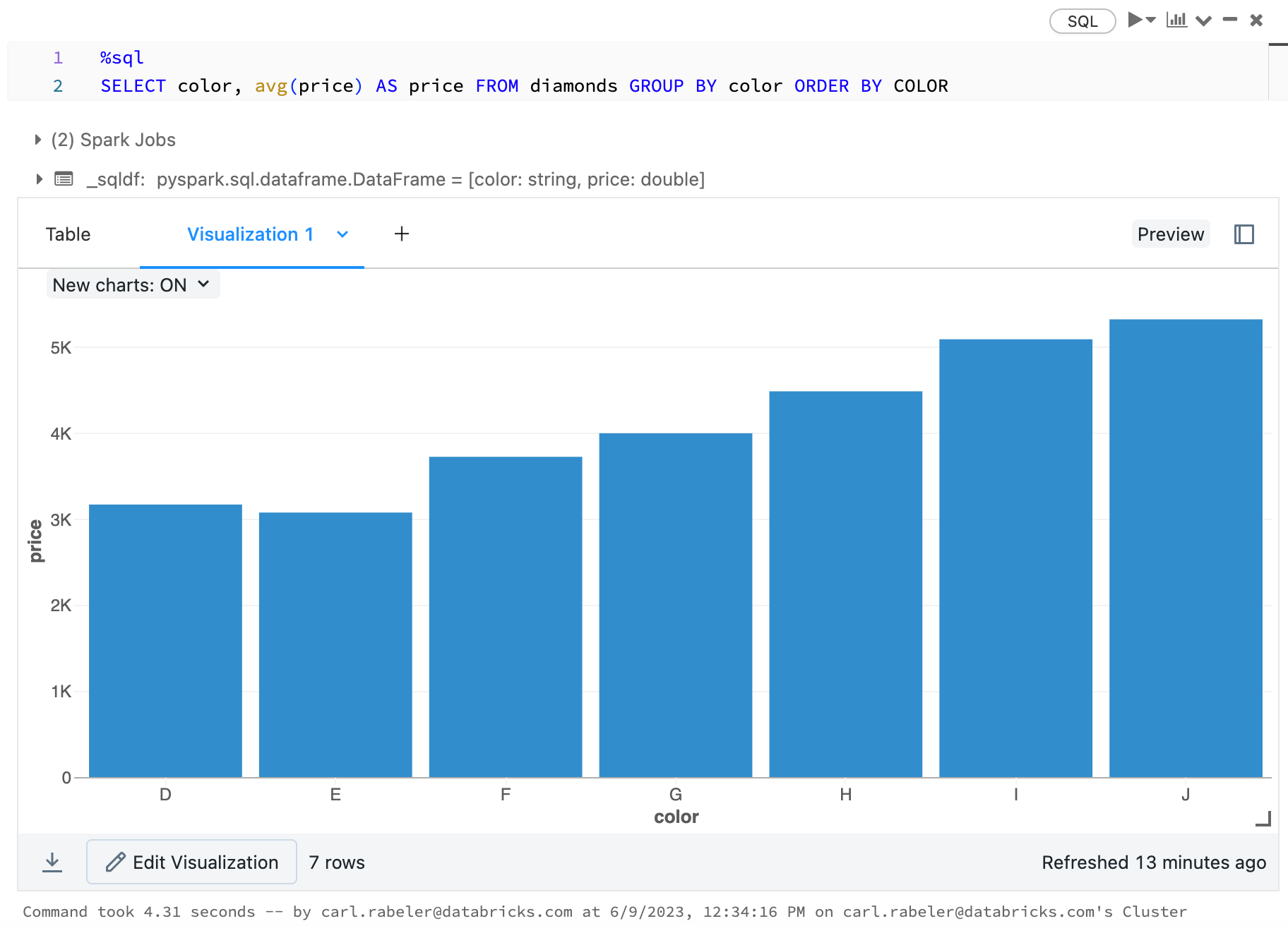
Step 4: Visualize data
Display a chart of the average diamond toll by colour.
-
Click the Bar chart icon
 .
. -
Click Plot Options.
-
Elevate color into the Keys box.
-
Drag price into the Values box.
-
In the Aggregation drop-down, select AVG.

-
-
Click Employ to brandish the bar chart.
Step five: Transform data
The best way to create trusted and scalable data pipelines is to utilize Delta Live Tables.
To learn how to build an constructive pipeline and run it end to end, follow the steps in the Delta Live Table Quickstart.
Pace 6: Set upwardly information governance
To control access to a table in Databricks:
-
Utilise the persona switcher in the sidebar to switch to the Databricks SQL surround.
Click the icon below the Databricks logo
 and select SQL.
and select SQL.
-
Click the
 Data in the sidebar.
Data in the sidebar.
#. In the driblet-down list at the peak right, select a SQL endpoint, such as Starter Endpoint. in the sidebar.
-
Filter for the diamondscsv_ table you created in Step 2.
Type
diain the text box following the default database.
-
On the Permissions tab, click the Grant push
-
Requite
All Usersthe ability to SELECT and READ_METADATA for the table.
-
Click OK.
Now all users tin can query the tabular array that you created.
Step 9: Schedule a chore
You can schedule a job to run a data processing task in a Databricks cluster with scalable resource. Your job can consist of a single job or be a big, multi-task application with complex dependencies.
To learn how to create a task that orchestrates tasks to read and process a sample dataset, follow the steps in the Jobs quickstart.

How To Set Up An Engineering Notebook,
Source: https://docs.databricks.com/getting-started/data-engineer-quick-start.html
Posted by: massengillsatione.blogspot.com
0 Response to "How To Set Up An Engineering Notebook"
Post a Comment